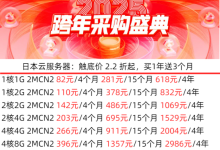
香港VPS,美国VPS,免费VPS国外服务器租用优惠码分享-主机测评
香港VPS,美国VPS,免费VPS国外服务器租用优惠码分享-主机测评
大模型服务器的配置需求会因具体的模型规模、应用场景和性能要求而有所不同。以下是一些一般性的配置推荐:
一、大模型服务器配置的硬件部分
1. CPU:
– 对于较大规模的模型训练和推理,选择高性能的多核服务器级 CPU 是很重要的。例如,Intel Xeon 可扩展处理器或 AMD EPYC 系列处理器。这些处理器具有较高的核心数量、时钟频率和大容量的缓存,能够处理大量的数据和复杂的计算任务。
– 如果预算允许,可以考虑配置多个 CPU,以提高并行处理能力。
2. GPU:
– GPU 在加速深度学习模型的训练和推理方面起着关键作用。NVIDIA 的 GPU 是目前深度学习领域最常用的选择,如 NVIDIA A100、H100 等。这些 GPU 具有强大的计算能力、高内存带宽和专门针对深度学习优化的硬件架构。
– 根据模型的规模和计算需求,可能需要配置多个 GPU。可以使用 GPU 服务器或通过 PCIe 扩展槽添加额外的 GPU。
3. 内存:
– 大模型通常需要大量的内存来存储模型参数、中间计算结果和输入数据。建议配置大容量的内存,例如 128GB 或更高。内存的类型和速度也会影响性能,可以选择高速的 DDR4 或 DDR5 内存。
– 如果使用多个 GPU,确保服务器具有足够的内存来支持 GPU 之间的数据传输和共享。
4. 存储:
– 快速的存储系统对于加载模型和数据非常重要。可以选择高速的固态硬盘(SSD)作为系统盘和存储模型文件的主要存储设备。NVMe SSD 具有更高的读写速度,可以显著减少数据加载时间。
– 对于大规模的数据集,可以考虑使用存储区域网络(SAN)或网络附加存储(NAS)来提供额外的存储容量和可扩展性。
5. 网络:
– 高速的网络连接对于分布式训练和数据传输至关重要。可以选择支持高速以太网(如 10GbE、25GbE 或更高)的网络接口卡(NIC)。
– 如果使用多个服务器进行分布式训练,可以考虑使用高速的网络交换机来连接服务器,以确保低延迟和高带宽的数据传输。
二、大模型服务器配置的软件部分
1. 操作系统:
– 选择适合服务器硬件的操作系统,如 Linux(例如 Ubuntu、CentOS 等)。Linux 具有稳定性、安全性和对高性能计算的良好支持。
2. 深度学习框架:
– 根据你的需求选择合适的深度学习框架,如 PyTorch、TensorFlow 或 JAX。这些框架提供了丰富的工具和库,用于构建、训练和部署深度学习模型。
3. GPU 驱动和库:
– 安装正确的 GPU 驱动程序和相关的深度学习库,如 CUDA 和 cuDNN(对于 NVIDIA GPU)。这些库可以充分发挥 GPU 的性能,并提供加速计算的功能。
4. 分布式训练框架:
– 如果需要进行大规模的分布式训练,可以考虑使用分布式训练框架,如 Horovod、PyTorch Distributed 或 TensorFlow Distributed。这些框架可以帮助你有效地利用多个服务器和 GPU 进行并行训练。
5. 监控和管理工具:
– 安装监控工具,如 nvidia-smi、htop 等,以实时监测服务器的硬件状态和资源使用情况。还可以使用管理工具,如 Kubernetes 或 Docker Swarm,来管理服务器集群和部署深度学习应用。
请注意,以上配置建议仅供参考,实际的配置需求可能会因具体的模型和应用场景而有所不同。在选择服务器配置时,建议根据你的预算、性能要求和可扩展性需求进行综合考虑,并进行充分的测试和优化。此外,还可以咨询专业的硬件供应商或深度学习专家,以获取更详细和个性化的配置建议。