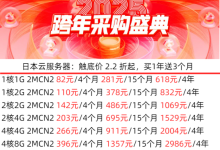
香港VPS,美国VPS,免费VPS国外服务器租用优惠码分享-主机测评
香港VPS,美国VPS,免费VPS国外服务器租用优惠码分享-主机测评
训练大型机器学习模型,尤其是深度学习模型,需要非常高的计算能力,通常需要使用到具有高性能GPU的服务器。以下是几种适合训练大模型的服务器推荐:
1. NVIDIA DGX A100:NVIDIA的DGX系列专为AI和深度学习设计,DGX A100配备了8个NVIDIA A100 Tensor Core GPUs,每个GPU都带有40GB的HBM2内存,总共可提供320GB的GPU内存。此外,它还配备了AMD的64核CPU和1.5TB的系统内存,非常适合进行大规模模型训练。
2. Google Cloud AI Platform:谷歌云提供的AI平台允许用户在云端训练和部署机器学习模型。它支持各种规模的模型训练,从小型实验到大型分布式训练。用户可以根据需要选择不同的计算资源,包括具有强大NVIDIA GPU的实例。
3. AWS EC2 P3/P4 Instances:亚马逊的EC2 P3和P4实例提供了高性能的NVIDIA V100和A100 GPUs,非常适合进行深度学习训练。这些实例支持多种配置,可以根据训练任务的具体需求进行选择。
4. 阿里云GPU云服务器:阿里云提供的GPU云服务器配备了NVIDIA Tesla V100、A100等高性能GPU,适用于深度学习、科学计算、图形渲染等场景。用户可以根据自己的需求选择不同的GPU数量和配置。
5. 腾讯云GPU服务器:腾讯云GPU服务器提供了多种配置选项,包括搭载NVIDIA Tesla V100、T4等GPU的实例,适用于AI训练、图形处理和高性能计算等场景。
选择哪种服务器取决于你的具体需求、预算以及是否需要云服务的灵活性。如果你需要一个高度可扩展且易于管理的解决方案,云服务可能是最佳选择。而对于需要极高计算性能和定制化硬件配置的场景,购买或租赁专用的高性能服务器(如NVIDIA DGX系列)可能更加合适。